 |
UTSUNOMIYA_NLP研究所
宇都宮からディープラーニングを始めとする機械学習・AI・自動化・仕組化・ツール作成についての情報を配信。python学習を始めたい方。チェックしてください。
2021年11月30日 UTSUNOMIYA_NLP研究所
この記事では企業活動において、ディープラーニングで何ができるかと、何をどの程度理解すればいいのか、何に適用できて恩恵がどの程度ありそうかについて記載しております。 結論としては、ディープラーニングは分類と回帰に強いため、情報の収集とその加工分析の両方でディープラーニング技術が効果を発揮します。 使いこなすのには技術理解が必要であり、中途採用や内部育成のどちらにおいても、組織内に風土として定着するまでにそれなりの時間がかかると考えます。 一方、企業内にはルールベースで自動化できることがたくさんあり、短期的にはDXという文脈においてそちらを優先すべきかもしれません。
ディープラーニングで、できる(自動化・精度向上できる)こと とは。
ディープラーニングと機械学習
機械学習とは、古典的な統計解析を含む統計解析手法の総称です。
機械学習の方法の1つとして ディープラーニング があります。
以下にて、目的による代表的な手法をいくつか紹介します。
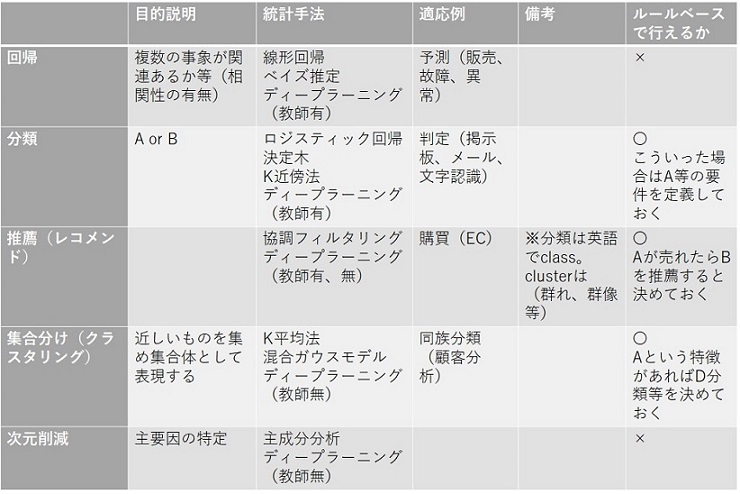
ディープラーニングは上記に含めていないが、上記のほとんどの目的に対しての適用研究がなされており、いずれにおいても精度向上が見られます。 特に分類・回帰・生成においては、特筆すべき成果が立証されております。 ディープラーニングは脳のニューロン(ニューラルネットワーク)を模した構造です。 その構造は複数あり、NN、CNN、RNN、GAN、BERT 等 が代表的な構造例ですが、GAN のみは 生成 という新しい目的を獲得しているモデルといえます。 またその学習方法としても 強化学習 というアプローチがあります。 具体論として、目・耳・口・鼻・手 という5感に置き換えて説明しなおした場合には、分類の果たす役割が大きいため、必然的にディープラーニングがパワフルな役割を果たすこととなります。
- 目:画像認識・言語処理(分類 等)
- 耳:音声認識(分類 等)
- 口:音声発話・言語処理(生成 等)
- 鼻:成分分析(分類 等)
- 手:ロボット制御
実務での適用において弊害となる点
社内に知見のあるメンバーがいれば、問題ありませんが、知見を独学で獲得しようとするとなかなか容易ではありません。 中途採用か内部育成、いずれにしても会社の長期的な競争優位の確立のため、AI人材の内製化は必須であると著者は考えます。 開発は外注できますが、コントロールできなければ長期的な会社への恩恵は薄まるでしょう。 中途採用は機会次第ですが、テック系企業の報酬体系と比較し、社内に報酬制度を内製化できるかは大きな課題です。 条件・定着等の観点から長期で貢献してくれるかは、現状の国内転職市場を見ますと、疑問視される情勢かもしれません。 独学を例にしますと、ディープラーニングの理論の学習と身になる実践自身において、時間を要することもあり、社会人として業務と両立しながら自身で学習していくのは、時間確保・継続という点でかなりの根気を要します。 ディープラーニングにそもそもの関心が高い方であっても、一人で向き合うのは容易ではないかもしれません。 pythonのモジュールを触りながら手ごたえを掴むのが、一番早いと思われますが、プログラム初学者では、pythonの実行環境を整えるだけでも苦労があるかもしれません。pythonの動き方とディープラーニングがpythonのどの程度の記述量で実行されうるのかの要諦を教わるだけでも理解はかなり促進されると考えられます。 スクール・講座(WEB講座含む)を活用するのも一考です。 一方、自身でプログラムを触れる方であれば、関連するモジュール(pythonの拡張機能、ライブラリに相当)を実際に触って動かしてみることを、強くお薦め致します。 ディープラーニングに際して活用される、代表的なpythonモジュールは以下です。
- ・pandas 主に表計算用途として活用される。
- ・numpy 配列処理に活用される。ディープラーニングは配列処理(ベクトル処理)が必須であるため。
- ・pytorchやtensorflow どちらもディープラーニングの代表的なモジュール。どちらかで良い。
- ・scikit-learn 主に機械学習(ディープラーニング以外)を提供してくれるモジュール。
- ・scipy 協調フィルタリングを使う際は利用
- ・flask 機能を最低限に絞った軽量フレームワーク。必要な機能は追記していくことで中規模の開発まで対応可能。 ※もしくは django 大規模開発向け
仕事現場での適用の考え方
自動化を実務目線で考えた場合には、そもそも機械学習を用いることがその業務の自動化との相性がいいのかという問題があります。 機械学習は上記の目的から分かるように、複雑な物事の原因について人間の言葉で具現化できない(説明・言語化できない)ことの説明枠組みとしてパワフルに機能します。 結論として、人間が言語でルール化できる部分については、機械学習を用いる必要はありません。 ルールベースで処理をすることができることを意味し、ルールベースであるということは、プログラミング可能であることを意味します。 一方、業務の自動化という観点では、ルールが決まっていて自動化できるが、現実問題として機械学習がパワフルに活躍するというシーンがあります。 それは、商慣習が完全なデータのやり取りであれば、不要となるような事例が現実問題としてほとんでです。 具体的な例としては請求書から振り込みデータを作成することはデータを処理するルールが明確であり可能であるが、現実の請求書から書面上の位置を特定し、項目・金額・振込期日等の記載内容を拾うことは画像認識等を用いないとできないというようなジレンマが発生します。 これは近い将来に商慣習での請求書のやり取りがお互いの会社のWEB(API)を介してなされる等の処理方法であれば、現在の商慣習はより、人手を介さず、正確で早い処理となります。 そのような未来はもうすぐそこまで来ていると考えられます。 請求書の処理は画像認識でフォローされますが、極論はデータの直接的なやり取りで、解消される未来も近いため、変化との時間軸と投資・削減費用の兼ね合いで投資判断することが肝要です。 機械学習の現場適用を検討するに際しては、目的と手段で検討しますが、手段においてもディープラーニングを用いた技術の恩恵に預かれる可能性があります。 目的と手段と手段の実行方法 等の細部の作業内容と、なぜ人手を介さないといけないのか、人は何を確認・判断しているのか、それは自動化できないのかを棚卸しすることが必要となります。
仕事現場での適用の進め方
検討するに際しては、機械学習が適用できる分野への知見が求められることもあり、 現実的には、既に適用されている情報を纏め、その方法論を含め自社に取り入れていく作業が時間効率や確実性の観点からは有用かもしれません。 一度、タスクの洗い出しを行ったうえで、 自動化すると時間削減の効果が高く検討すべきもの と方法が確立されていて自社に取り入れるもの から検討を着手するのが適切です。 職場の機運を高めるためには、既に他社で適用している事例から学び、 手始めに自社に適用していくのがプロジェクトが進むきっかけとなるでしょう。 既に職場適用に実績があるディープラーニングの活用事例は以下が代表的です。
- ・売上予測、在庫予測、価格設定(回帰)
- ・異常検知(画像処理)
- ・コールセンター等でのテキスト化(音声認識)と分析
- ・テキスト文章のファイル仕分け(分類)
- ・WEB掲示板、コメント欄等の監視(言語処理)
- ・画像ファイルの仕分け(画像処理、分類)
- ・翻訳(言語処理)
- ・教育のコンテンツ推薦(レコメンド)
- ・通行人数のカウント(画像処理)
- ・アイドルやイラスト等の画像生成
- ・CRMでの営業コンテンツの推薦(レコメンド)
フロント技術としての画像処理と音声認識や自然言語処理がディープラーニングで飛躍的にパワフルになり、 その情報を入口とし、情報内容に対し回帰や分類の精度が更にディープラーニングで向上するという 累乗的な飛躍さが上記の記述からも見て取れます。 例にあげると実際はそこまで多くないという印象を持たれる方もいらっしゃるかもしれません。 職場では人に最適化された非データ(先の紙の請求書 等)の書類が多い現状です。 一方、Saas等のWEBビジネスが一般化され、企業間や企業内の処理のデータ化が今後進むことが予想され、飛躍的(累乗的)に自動化が進むと想定されます。 社内の管理部門は機能毎のAPIで他部署に提供され、マイクロサービスとなります。 マイクロサービスで企業の枠を超えて連携し、商取引のバックオフィス的な仕事事態は、データ処理の受け渡しと受領という形態となることでしょう。
推進チームとシステム部門との分担の在り方
推進チームの座組を考えるうえでは、システム部門の関与は重要です。 最終的な自動化は間違いなくシステム(WEBサービス、アプリ、処理スクリプト等)を通じて提供されます。 システム部門の役割ですが、担当者によっては要件定義を求めてくる方がいらっしゃいます。 これは見えている目線の置き方の違いによるものです。 自動化を推進するに際しては、必ず捉えておかないといけない問題です。工数が多い対応事項に対し、手戻りまであるようでは埒があかないという気持ちになるのは当然かもしれません。 システム担当の目線で見た際には、運用・開発(手戻り)・コーディング・セキュリティ・インフラ と多岐に渡ります。 工数面は、実際に非システム担当の目線と比較して見た場合よりかなり多いという印象になることがあることが主な要因であると著者は考えます。 昨今ではノーコードツールの台頭もあり、非システム担当の方も積極的に自身の業務を自動化することが、両者の溝を埋めるうえでは良いアプローチかもしれません。 フロントのWEB周りの処理がなく、データの加工・ディープラーニングの適用に対して、処理を考えていくだけであれば、システム担当にとってはかなりの工数減と感じられるでしょう。 また全社的な取り組みとしていくに際しては、AI学習やプログラム学習を、システム部門の人材以外の選抜メンバーに対し投資していくことは、長期的な会社のコアコンピタンスを築いていくことにつながるでしょう。 最初はノウハウの確立に向け、外部活用も検討してもいいかもしれません。
推進チームと遊び心
実務にも大変役に立つ事例ですが、kaggle という機械学習で精度を競うWEBサイトがあります。 コンテンツとしてデータが提供されると同時に、pythonの実行環境、計算リソースとしてのGPU等が提供されており、実務能力の向上にはもちろんですが、視野を広げるうえでも大変有用です。 成績上位者のコードが公開されていたりもしますので、自己学習に最適です。 一方、著者の感想としてはpython学習の初めでふれてしまうと、ややハードルが高すぎるかなという印象です。 pythonに慣れたあとに挑戦しても遅くはないですし、最初はpythonに慣れることを優先されてもいいかもしれません。
©dhipithi Inc All rights reserved.